

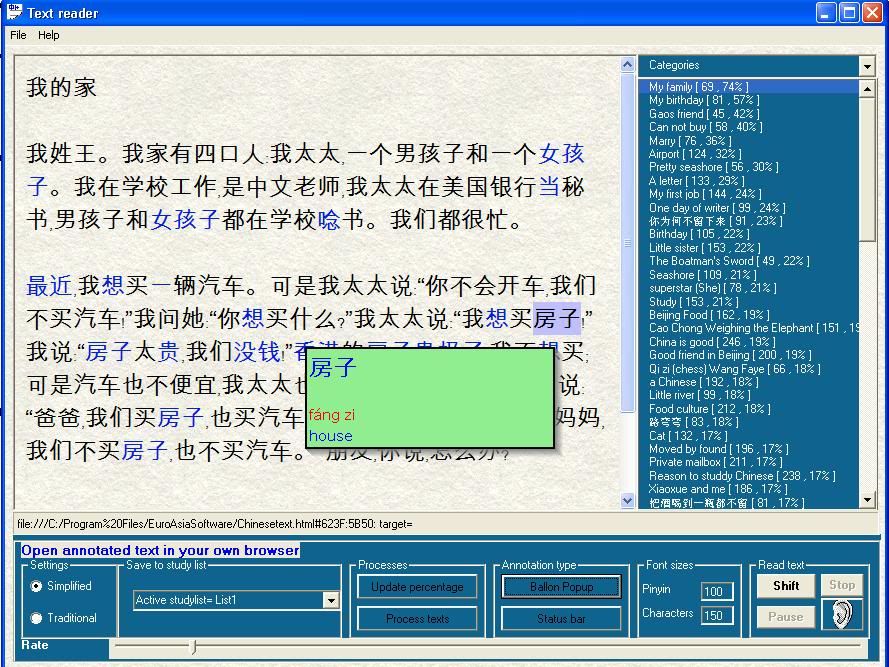
To just learn characters without using them is not a good practice so I try to read as much as possible. Many years ago i did write a program that parsed Chinese texts i had in a database and gave me a list with texts and the percentage of known words in that text. Then I could choose suitable texts for the level I where at for the moment. In the texts words/ characters that where not known by me where linked to a dictionary and also had a translation popup etc. It would be great to be able to use something similar in skritter. Maybe just list example sentences with many characters/words i do know. This is most suitable for beginners/ elementary learners with a limited vocabulary but at that stage i feel that it is very important to really use the language an read a lot. For now I will try to find my old code and dust it of;-)
Feature request
Mandarinboy
August 17th, 2010 9:21p.m.
Lurks
August 17th, 2010 9:44p.m.
Mandarinboy
August 17th, 2010 10:01p.m.
{kind=link}
nick
August 18th, 2010 7:54a.m.
skritterjohan
August 19th, 2010 3:59a.m.
nick
August 19th, 2010 7:52a.m.
ximeng
August 19th, 2010 9:20p.m.
Mandarinboy
August 19th, 2010 9:38p.m.
nick
August 20th, 2010 10:17a.m.
This forum is now read only. Please go to Skritter Discourse Forum instead to start a new conversation!